The Algorithm Breakdown
This algorithm is a heuristic approach designed to address the global routing problem, an NP-hard optimization problem. Due to the complexity of the problem, exact optimal solutions are infeasible, and heuristic methods are required to obtain good solutions within a reasonable timeframe. Thus, the algorithm relies on heuristics to approximate an optimal solution that satisfies the given constraints.
For this heuristic algorithm, there exists both stochastic property and deterministic property:
Stochastic: The algorithm employs random decision-making techniques, such as utilizing a pseudo-random number generator. As a result, it is highly probable that two separate algorithm runs will yield distinct solutions. Simulated annealing is a prominent example of a stochastic algorithm.
Deterministic: The algorithm’s decisions are deterministic, meaning that they can be repeated. Dijkstra’s shortest path algorithm is an instance of a deterministic heuristic.
And as for this heuristic algorithm’s structure, it is typically similar to the diagram below:
Solve the problem with constructive algorithm and create an initial solution
While the termination criterion is not met, do iterative improvement on the initial solution
Return best-seen solution
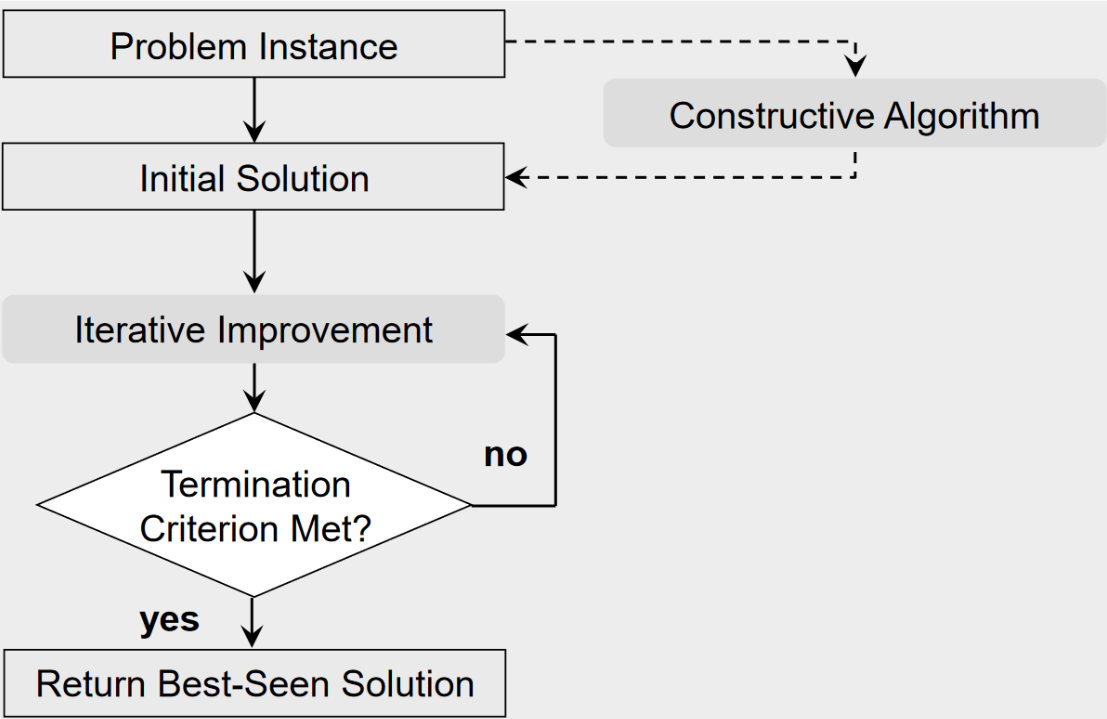
The algorithm employed in this project adheres to the structure and framework of a heuristic algorithm. In the subsequent discussion, a thorough explanation of each step and detail of the algorithm will be provided.
Firstly, upon receiving the netlist input, the global routing algorithm parses the supplied netlist file. Subsequently, it proceeds to construct and initialize essential data structures, including the grid data structure, which encompasses the grid size, horizontal and vertical capacities of the grid, among other attributes. In addition, the list of net data structures is established, comprising the net ID, net name, and coordinates of the two pins to be connected, among other relevant features.
Next, we aim to create an initial solution by routing a path for each net in the netlist, connecting the two pins of each net in the netlist sequentially. This will be the constructive algorithm part in the heuristic algorithm structure. The sequence of routing the nets is critical, as the output results in different wirelength and overflow values. Nonetheless, due to the inherent stochastic and deterministic properties of this heuristic algorithm, randomization can be employed to shuffle the net routing order for the stochastic aspect, hoping to generate high-quality output. Meanwhile, for the deterministic aspect, it is imperative to sort the netlist by the half perimeter wire length (HPWL). To clarify, HPWL refers to the summation of the Manhattan distances among all pairs of pins in the net. Sorting the netlist based on HPWL can considerably enhance the output result. Specifically, larger nets can be more efficiently routed around smaller ones that have already been routed, reducing routing impediments and optimizing the utilization of routing resources. Upon implementing the constructive algorithm, an initial solution can now be generated. However, this solution may be of sub-optimal quality, which necessitates undergoing iterative improvements in the subsequent stage.
The pin routing algorithm is responsible for creating the shortest possible path to connect the two pins of a net, while also ensuring that there is no overflow. To reiterate, overflow occurs when a wire is placed on a channel track that has reached its maximum capacity. When routing two pins with the shortest wire length, the most efficient path will typically be a straight line or L-shaped path. A naive breadth-first search algorithm can achieve this result without considering congestion information in channel tracks. This method ensures that all paths routed for all nets have the shortest possible wire length. However, since congestion information is not considered, the outputs will likely have a high overflow, which can negatively impact the quality of the output. To achieve an output with lower overflow, it is necessary to compute congestion data, which is the demand and capacity ratio on the channel track. This information must be considered when deciding the path to connect the two pins.
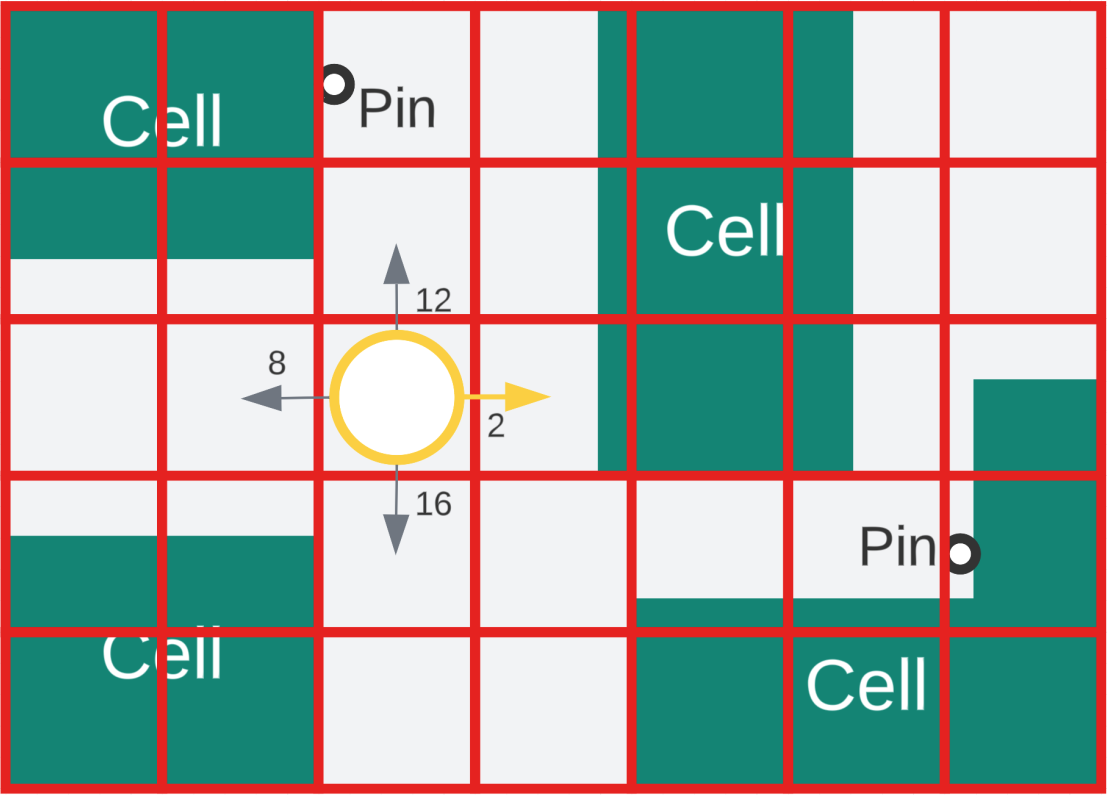
Consider the figure above, where the current node is depicted as a yellow circle. To reach the next node, any of the four directions can be considered. Assuming that the horizontal and vertical capacities are 14 and 16, respectively, the cost of reaching each adjacent node can be calculated. Moving east requires placing two wires on the channel track, while moving north incurs a cost of 12 wires. Moving west incurs a cost of eight wires, and moving south requires 16 wires. Notably, the south node has already reached its maximum vertical capacity, so traversing there would be prohibitively expensive. Therefore, the node with the lowest cost and a demand of only two is the east node.
To implement this, the Best First Search algorithm is used. The Best First Search algorithm is similar to breadth-first search, but it maintains a priority queue to keep track of the next node to be visited. The node with the lowest cost, which in this context is congestion data, is selected from the queue and expanded. This process is repeated until the goal node is found or there are no more nodes to explore. When expanding, the next node can be in the north, south, east or west direction, and the cost will be the demand of the edge to go to the next node. The node with a low-demand edge will have a low cost and be more likely to be chosen as the next node. If the edge’s demand has already reached maximum capacity, an enormous cost will be assigned to prevent it from being chosen as the next node.
The stochastic nature of the algorithm implies that the quality of the output generated by a run is uncertain. One idea is to leverage multiprocessing capabilities to execute multiple routing processes simultaneously. By generating several results with varied quality, each with a unique randomized net routing order, we can identify the most optimal solution among them. Subsequently, the best solution serves as the initial solution for the iterative improvement stage.
In this project’s context, the iterative improvement process is referred to as the ”rip-up and reroute” phase. This involves identifying the problematic nets that lead to overflow and ”ripping them up”, followed by re-routing attempts to reduce the overflow in the layout. The termination criterion for this stage is either when the overflow reaches zero or when the maximum number of rip-up and reroute attempts are reached. Upon satisfying the termination criterion, the resulting output is a complete set of paths for all nets with the best-seen quality yet.